2.1 Deskriptiv statistikk
2.1.2 Kommentarer
Deskriptiv statistikk handler ikke om analyse eller regning, men om å presentere kompleks informasjon på en effektiv måte. Det er altså noe ganske annet enn det vi ellers snakker om i kurset, men det er likevel et av de nyttigste læringspunktet vi har. Hvem kan ikke regne med å måtte presentere tall og resultater i løpet av sin karriere? Eller selge inn forslag og planer for overordnede i håp om å bli lyttet til? Det kan være direkte avgjørende for din egen gjennomslagskraft at du er i stand til å produsere overbevisende tabeller og figurer i slike situasjoner, og det er det dette temaet handler om.
I læreboken er det kapitlene 2–4 som behandler deskriptiv statistikk, men det er veldig Excel-fokusert, som ikke er så relevant for oss. Det er likevel ikke dumt å lese gjennom stoffet for å se hva det går i, og legg spesielt merke til følgende punkter:
- Ulike datatyper i avsnitt 2-1.
- 3-4: The art and science of graphical presentations. Hva er det som gjør en grafisk illustrasjon god? Prøv å ta inn over dere all informasjonen som vi lett kan lese ut av bildet på side 75 om Napoleons felttog mot Moskva. Her presenteres informasjon om tid, antall, geografi og temperatur på en helt eksepsjonelt effektiv måte! Videre er det noen grelle eksempler på hvordan vi kan bruke grafiske virkemidler til å gi skjeve fremstillinger. I videoforelesningen gir vi flere eksempler på dette.
- Kapittel 4 går litt mer i dybden om numeriske deskriptive teknikker, som gjennomsnitt, median, standardavvik, korrelasjon, osv. Dette skal være dekket greit i forelesningen, men boken går litt lenger.
Det kan være en fin øvelse å kikke på eksemplene i læreboken og forsøke å gjenskape noen av Excel-figurene i R. Se på eksempel 3.2, der man skal lage to histogrammer over historiske avkastninger for to ulike investeringsstrategier. Vi leser inn datasettet (last ned fra Canvas) som under og kikker på det:
## # A tibble: 50 × 2
## `Return A` `Return B`
## <dbl> <dbl>
## 1 30 30.3
## 2 -2.13 -30.4
## 3 4.3 -5.61
## 4 25 29
## 5 12.9 -26.0
## 6 -20.2 0.46
## 7 1.2 2.07
## 8 -2.59 29.4
## 9 33 11
## 10 14.3 -25.9
## # ℹ 40 more rowsHver stategi har sin kolonne. Merk at variabelnavnene har mellomrom i seg, noe som er upraktisk når vi jobber med et seriøst programmeringsspråk. En god vane er å rett og slett gi dem nye navn, ved f.eks. å kjøre colnames(returns) <- c("returnA", "returnB"), eller så må vi alltid referere til variabelnavnene ved å bruke slike “backticks” som vi ser under.
Vi kan lage to enkle histogrammer slik vi gjorde det i forelesningen:
library(ggplot2)
ggplot(returns, aes(x = `Return A`)) +
geom_histogram(bins = 10)
ggplot(returns, aes(x = `Return B`)) +
geom_histogram(bins = 10)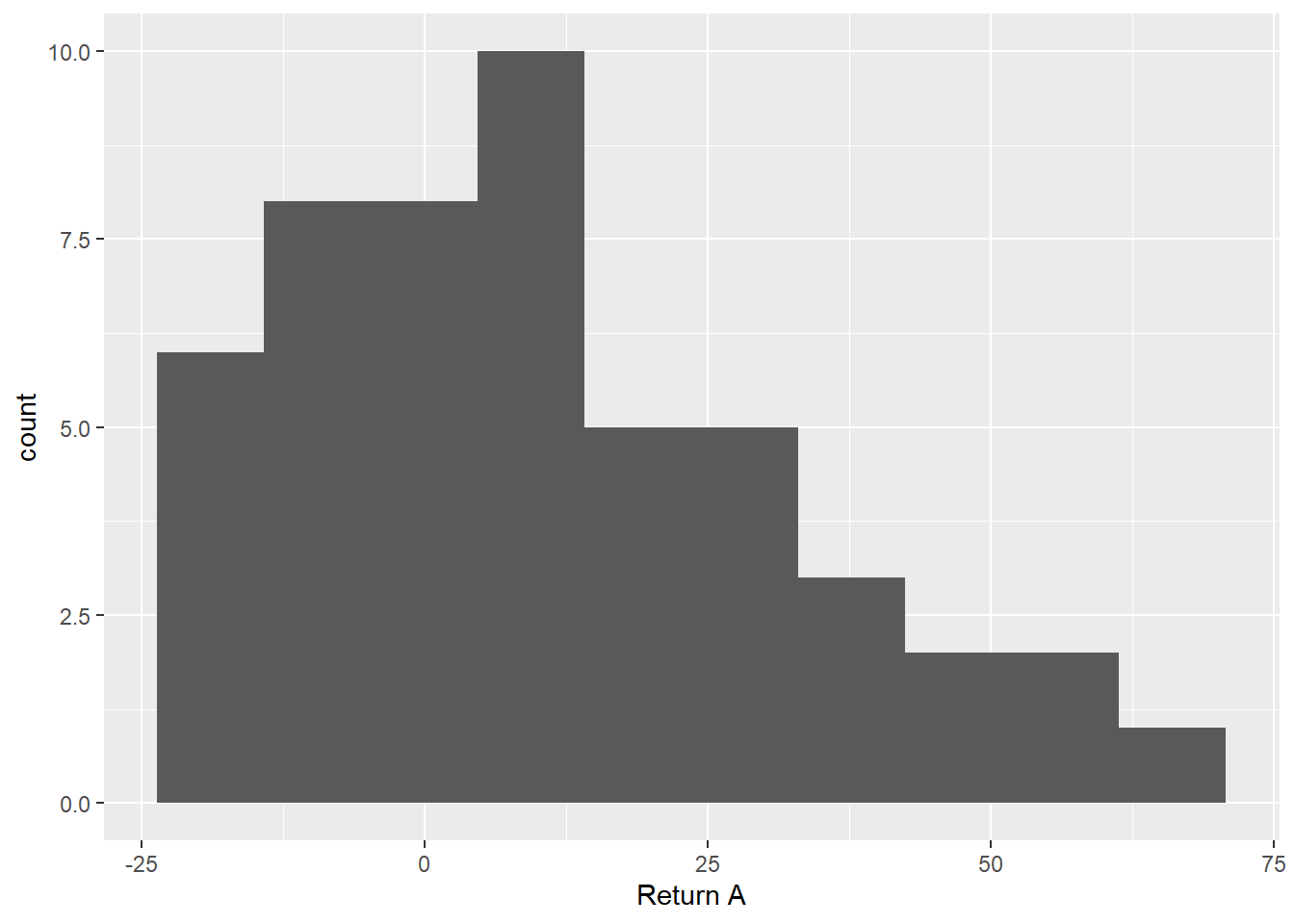
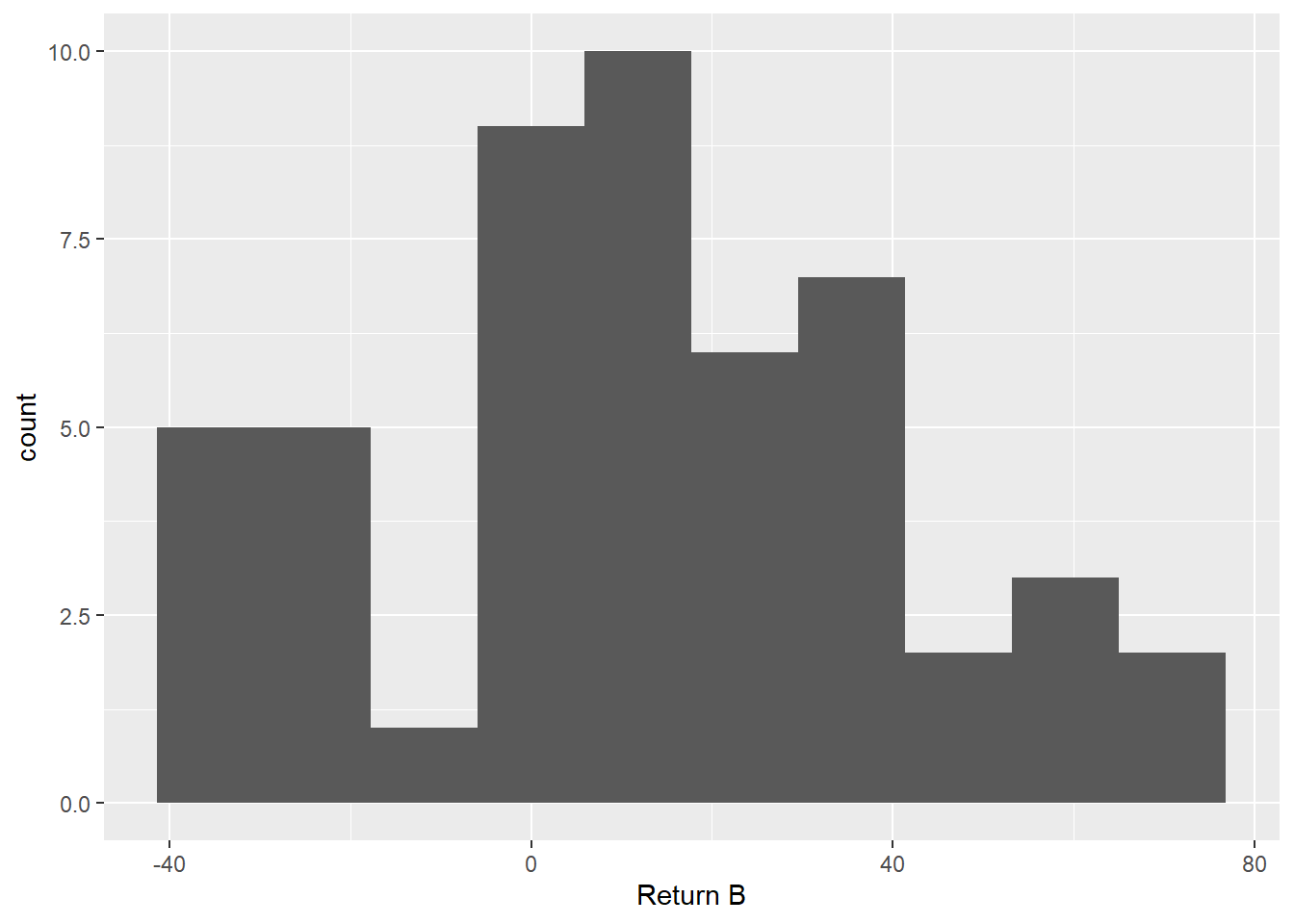
Figur 2.1: To histogrammer
Her er noen kontrollspørsmål som du kan prøve deg på:
- Hva er forskjellen på deskriptiv statistikk og statistisk inferens?
- Deskriptiv statistikk kan gjøres grafisk eller numerisk, eventuelt som tabeller av ulike numeriske mål. Nevn noen fordeler og ulemper man må veie mot hverandre når vi skal velge mellom grafisk og numerisk deskriptiv statistikk.