# A tibble: 59 × 11
Date NASDAQ ADBE AMZN AAPL BBBY CSCO CMCSA COST
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-0… -0.0101 -0.0329 -0.0696 0.0739 -3.64e-2 -0.0933 -0.0686 -0.0484
2 2013-0… 0.0494 0.127 0.107 -0.0217 4.79e-2 0.00513 0.0695 0.0291
3 2013-1… 0.0386 0.0430 0.152 0.0920 -5.17e-4 -0.0378 0.0535 0.0243
4 2013-1… 0.0351 0.0461 0.0781 0.0619 9.14e-3 -0.0598 0.0466 0.0611
5 2013-1… 0.0283 0.0532 0.0130 0.00886 2.87e-2 0.0540 0.0412 -0.0525
6 2014-0… -0.0176 -0.0116 -0.106 -0.114 -2.29e-1 -0.0235 0.0466 -0.0576
7 2014-0… 0.0486 0.148 0.00946 0.0500 6.03e-2 -0.00503 -0.0520 0.0388
8 2014-0… -0.0257 -0.0430 -0.0737 0.0198 1.43e-2 0.0280 -0.0324 -0.0448
9 2014-0… -0.0203 -0.0636 -0.101 0.0948 -1.02e-1 0.0303 0.0338 0.0352
10 2014-0… 0.0306 0.0452 0.0273 0.0702 -2.08e-2 0.0633 0.00846 0.00293
# ℹ 49 more rows
# ℹ 2 more variables: DLTR <dbl>, EXPE <dbl>Assignment 1
Note
This assignment is to be handed in as an .R-file through Canvas. Your answer will be reviewed by a teaching assistant as well as two fellow students. Do take the time to condsider the feedback. You will also receive two random answers from fellow students for review. Try to find one positive aspect as well as one suggestion for improvement in each of the answers. You must complete both peer reviews in order to pass the assignment.
Problem 1
We will look at the monthly returns on the NASDAQ composite stock index from August 2013 to June 2018, as well as the returns on 16 individual stocks listed on NASDAQ. The data is contained in the file data-nasdaq-returns.xls, and has been collected from the Yahoo Finance website.
Put the data in an appropriate folder on your computer. Perform the following tasks:
- Read the data into R and take a first look at the data set. The main index is in the
NASDAQ-column.
- Make a new data frame containing only the date column and returns on the main index as well as one of the individual stocks of your choosing. Name the new data frame appropriately.
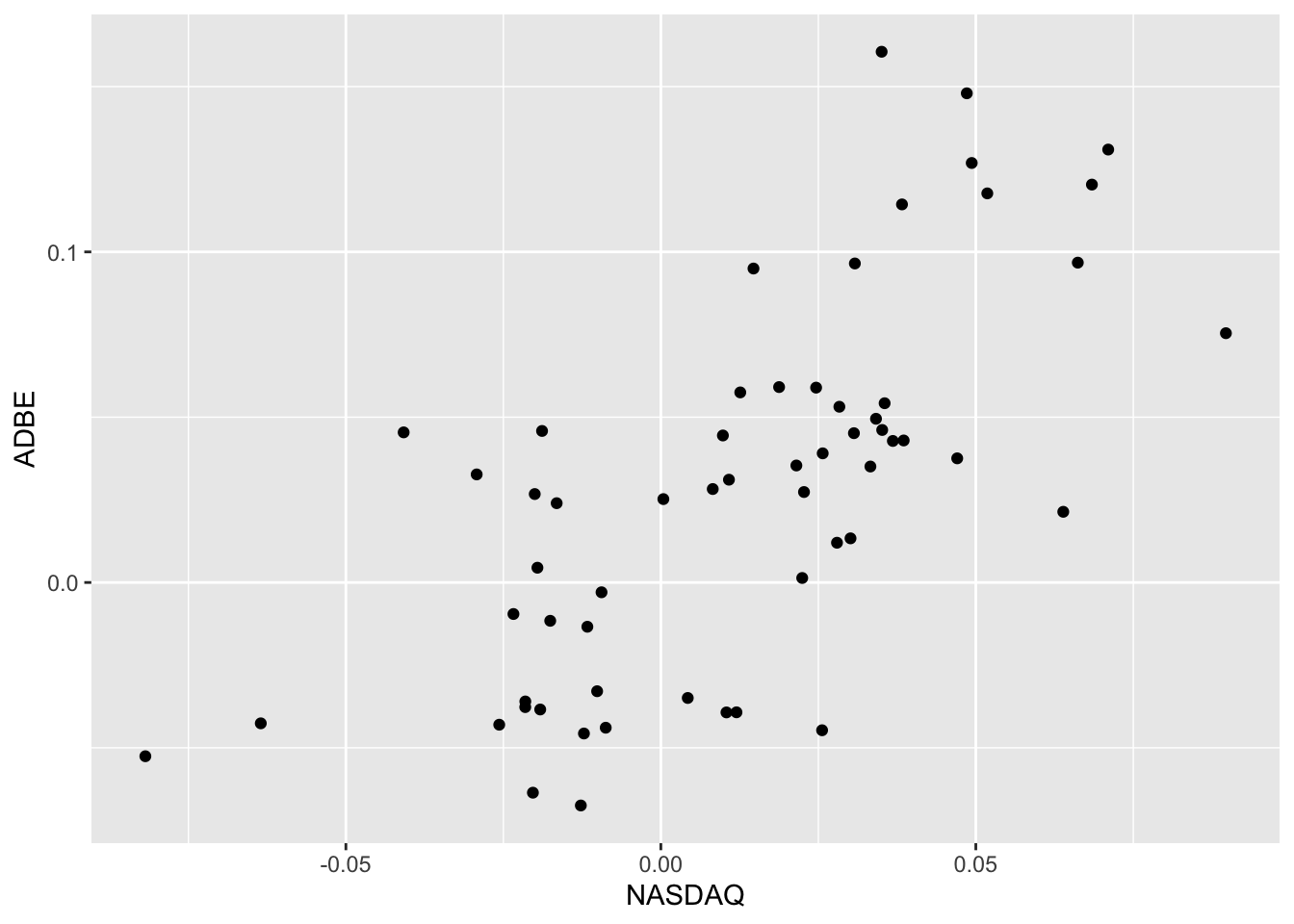
- Make a scatterplot of the two variables in your newly created data frame.
Click here to see the plot should look like.
Still, using ADBE, will of course look a bit different if you have chosen a different stock:
- The function
sign(x)returns the sign ofx, that is, it returns -1 ifxis negative and 1 ifxis positive. Make two new columns, namedsign_NASDAQand a corresponding name for the stock that you have chosen to include, that contains the sign of the return, indicating whether the index or stock went up or down that day.
- Make another column consisting of the sum of the two sign columns divided by two. The resulting value will then be -1 if both the index and the stock went down that day, 0 if they went in separate directions, and 1 if both went up.
- We would like to count the number of days for which the new
sum-column is either -1, 0, or 1. Do that by applying the functiontable()to thesum-column. (Recall that we can pick out individual columns using the dollar-sign).
- In the tasks above you may (or may not) have created several intermediate data frames under different names for each problem, or perhaps you have overwritten the data frame for each new task. Let us rather complete task 1, 2, 4 and 5 in one single operation, where you just append each task to the previous using the pipe-operator. That way you only need to come up with one name for the data set.
Problem 2
The .csv-file (comma separated values) is a common format for storing data in a plain text file. The file data-missile.csv contains data on North Korean missile launches from 1984 until 2017. Put the file in folder on your computer and inspect the contents by opening it in a text editor such as Notepad or Textedit.
R ships with a function read.csv() that we can use to read csv-files in the same way as we use read_excel() to read excel-files. We will, however, use a function from the readr-package called read_csv() for this purpose that does almost the same thing as the default read.csv()-function. There are some subtle differences between these two functions that are not very important, but read_csv() works a little bit better together with many other functions and packages that we will use later.
Load readr using the library() function. If you get an error message telling you that there is no package called 'readr', then you need to install it first using the install.packages()-function.
Load the data into into R using the following command:
missile <- read_csv("data-missile.csv")Look at the data. The variable «apogee» is the highest altitude reached by the missile in km. Calculate the following statistics for this variable:
- The mean.
- The median.
- The standard deviation.